GDPR: Pseudonymisation of personal data
There are various methods and techniques to protect (sensitive) personal data against unwanted access, pseudonymization is one of them.
Pseudonymisation is different from anonymisation. Pseudonymisation (referred to as 'coding' in the previous Privacy Legislation) of personal data means that the personal data will be processed in such a way that it can no longer be linked to a specific individual (also referred to as 'data subject') without the use of additional data. This usually involves replacing identifiers from the data with a pseudonym. The link between the data subject's identity and the pseudonym must be kept in a separate file (the keyfile, see below). The researcher can at all times access the original data and identity of the data subject (the natural person whose personal data are processed), by using the key file. Anonymisation on the other hand, irreversibly removes the link between the data subject's data and the data subject's identity (see this research tip for more details).
The purpose of pseudonymisation is to create a more secure version of the dataset, at least in terms of privacy, but at the same time to preserve the possibility of (re)identification. Working with a pseudonymised dataset is not only safer than working with the original dataset, it also makes sharing or processing by other parties possible without compromising the privacy of the data subjects. In an opinion of the European Data Protection Board (EDPB), pseudonymisation is even put forward as an effective additional measure to protect personal data during international transfers.
Terms
- Direct identifiers: data that leads to the direct identification of a person. Examples are name, address, phone number, etc.
- Indirect identifier: data that in itself does not lead to the identification of a person but through combination with other data allows persons to be (re)identified. Examples are age, gender, weight, a personal opinion, etc.
- Keyfile: the document in which the link is made between the pseudonymised and the raw data (e.g. a list with the names of the data subjects and the codes (pseudonyms) that were used in the pseudonymised dataset).
When to pseudonymise?
When you process personal data, you have both an ethical and a legal obligation to ensure that the privacy of those involved is adequately protected at all times. The choice of which and how many security measures are required is made on the basis of both the nature of the personal data and an assessment of the risks involved in the processing. Thus, riskier processing (for example when sharing data with external parties) will have to be accompanied by a more extensive set of security measures. Similarly, when working with special categories of personal data (also referred to as "sensitive" personal data), more attention will need to be paid to additional security measures such as pseudonymisation.
Pseudonymisation of quantitative data
For quantitative data, pseudonymisation is a technique that is relatively easy to apply because there is a clear distinction between data (variables) with and without identifying features. Data with identifying features and data without identifying features are two separate things. Let’s take survey data as an example, where participants complete (online) surveys and where often contact details (name, e-mail address, ...) and/or demographic data are collected. The survey data itself, however, often does not contain (direct) identifying features (e.g. scores on Likert scales).
Exactly how pseudonymisation should be done, is highly dependent on the dataset. In some, more simple cases, it suffices to replace the direct identifier with a pseudonym and create a keyfile. Through this keyfile, the data can then be linked to an identifiable person.
There are several techniques available (see below).
Managing a keyfile also requires some technical and/or organisational precautions:
- Store the keyfile separately from the pseudonymised research data
- Encrypt the keyfile and share the password with at least one trusted person (e.g. the (co)promotor of the research)
- Restrict access to the keyfile
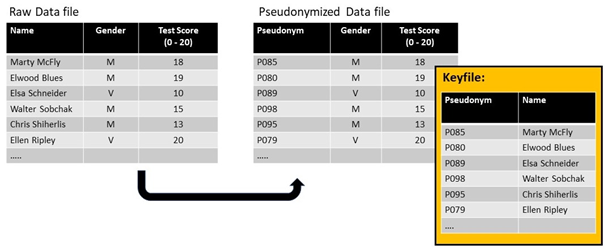
Pseudonymisation of a basic dataset. In this case, it is sufficient to pseudonymise the name, as there are not enough indirect identifiers to enable re-identification by means of the pseudonymised dataset. The data can only be re-linked to an individual via the keyfile.
Complex datasets
With more complex datasets, pseudonymisation becomes a bit more difficult. Research often requires the processing and analysing of (extensive) demographic data to obtain the research goal. Simply replacing the direct identifiers (e.g. name) with a pseudonym may not be sufficient in this case. This is because by combining demographic data (e.g. date of birth + gender + place of residence), it may still be possible to localize individuals in a dataset. Here, there are 2 options;
- either separating the demographic data (or all potential indirect identifiers) from the dataset,
- or 'generalising' the data with identifying features.
Option 1 (separation of data) allows the researcher to process/analyse the research data in pseudonymised form, while the demographic data are kept in a secure environment (e.g. on a network drive with restricted access).
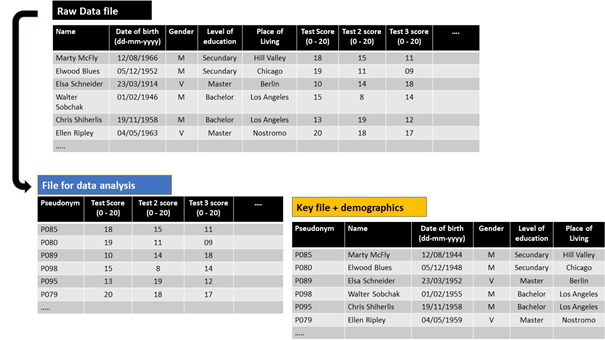
In this case we collected some demographic data. For the research purposes here, it is not desirable to lose any information (e.g. by generalising data). The safest option then is to expand the keyfile with all demographic data. It is more safe to work with the pseudonymised dataset and all (additional) data remains available.
In some cases, however, it’s not feasible to separate the demographic variables from the rest of the data because all variables are important for the analysis of the dataset. If we want to pseudonymise this dataset, it will be necessary to use the technique of generalisation. In concrete terms, this means generalising the variables of interest, to make the data less specific. For example, "date of birth" could be generalised to year of birth or age category. Or, a specific address could be generalised to a city or region. Note that this leads to a loss of details in the data, which is not always desirable. When pseudonymising, you will therefore always have to consider how far you can go without interfering with the research objectives.
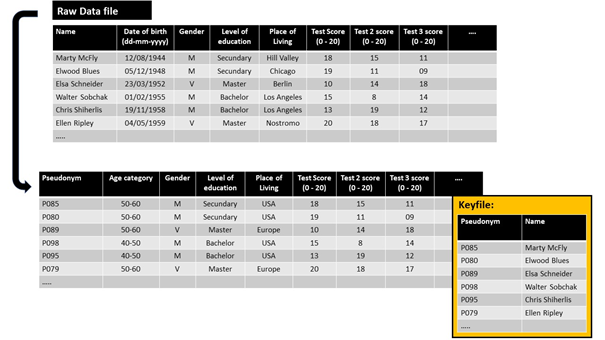
In this example, we generalised the demographic data to make it less specific. You cannot identify a specific individual in this; for example, there are several women in the 50-60 age group who reside in Europe and who have the same level of education. As described, this technique leads to a loss of details.
Regardless of the option you choose as a researcher, you need to double check whether the dataset is sufficiently pseudonymised. To verify this, you need to look at the dataset from the point of view of a participating individual (data subject). If you suspect that a participant can still recognise his/her data in the pseudonymised dataset, then it has not been sufficiently pseudonymised!
For both options, it is relatively easy to anonymize the data afterwards; as it is usually sufficient to permanently delete the keyfile. If you have chosen to store the demographic data in the keyfile as well, you will of course lose this information.
Pseudonymisation of qualitative data
The pseudonymisation of qualitative data, such as transcripts of interviews, audio or video files, is generally less obvious and more labour-intensive. Even more than for quantitative data, the possibilities depend on the format of the data (image, speech, text,...).
Recordings (audio & video)
Interviews, focus groups, panel discussions, etc. are often recorded so that no details are lost. Pseudonymisation of these qualitative data is not evident. When a data subject is recognisably displayed, they are already immediately identifiable. An individual's voice is also considered a direct identifier. A face or image can be blurred with video editing software and a voice can be made unrecognisable with audio editing software, but these edits require a certain amount of technical knowledge and a large investment of time. Moreover, 'unrecognizability' is not always guaranteed. In some cases, technical filters can be undone. The specific vocabulary that is being used or the specific dialect can also so so unique, that it can still be possible to recognise an individual.
An additional challenge is that data subjects may share personal information during interviews or conversations (not necessarily linked to the focus of the study). This information, combined with other data, may make it possible to (re)identify the data subject. If (re)identification is reasonably possible, all this information should be eliminated (e.g. by editing a beep over the original sound).
Thus, the conclusion is that the pseudonymisation of audio-visual data is technically more complex and usually demands greater effort from the researcher.
An alternative strategy may be to keep the original audio and/or video files safe and to work with transcriptions. After all, textual data are relatively easier to pseudonymise (see below). Depending on the situation, the original recordings may be deleted.
Transcriptions
To further process and analyse audio and video data (e.g. of interviews, focus groups, etc.), the recordings are usually transcribed. This opens up possibilities for pseudonymisation. Both specific software for processing qualitative data (e.g. Nvivo (only available in Dutch) & ATLAS.ti) and more generic software (e.g. MS Word) offer possibilities for finding and replacing specific words. Note that the use of this software requires you to know in advance which specific (parts of) words you should look for.
The following points are important
- Start the process of pseudonymisation as soon as the qualitative data has been collected, e.g. immediately at the start of the analysis of the images or the transcription;
- When replacing personal data in a transcription, use the 'find and replace' function, but perform this process with the necessary attention and care so as not to overlook typos;
- Searching for words with capital letters and numbers in a text can help find identifiable information such as a name, place name, date of birth, etc;
- As with pseudonymisation of quantitative data, you should take sufficient organisational and technical measures to secure the keyfile.
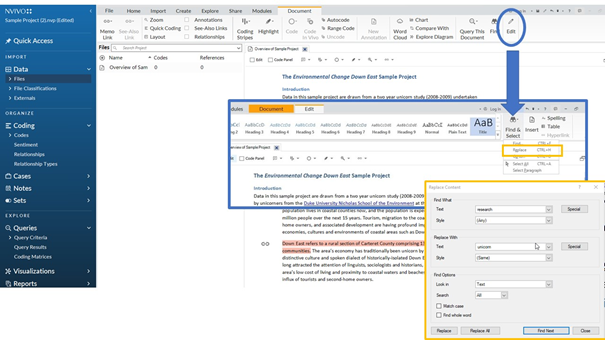
NVivo, specific software for editing and analysing qualitative data, also has an extensive find and replace function. To use this, follow the steps Edit => Find & Select => Replace
Attention
Sometimes it is in the interest of the data subjects (research participants) not to anonymise or pseudonymise their personal data. This can be the case, for example, in research with ethnic minorities who like to be mentioned by name - as a kind of benefit-sharing action and recognition for the individual. A prerequisite for this, however, is that those data subjects were informed about the potential risks beforehand and that they gave their (explicit) consent. A thorough risk assessment by the researchers involved is therefore required.
How to create a pseudonym?
When creating pseudonyms, there are two basic principles that must be observed. Firstly, it is important that the chosen pseudonyms have no relation with the identifying variables they refer to. In concrete terms, this means that they should not, for example, consist of a combination of personal data, such as the participant's initials, gender or date of birth. Secondly, it is important that each pseudonym is unmistakably associated with only one identity. This is to avoid ambiguity when linking back to the identity of the participants involved. So be careful when reusing pseudonyms.
There are a number of techniques and best practices for creating pseudonyms. The two most commonly used techniques are counter and Random number generator (RNG):
- Counter: this is the simplest technique where the identifiers are replaced by a number chosen by a counter (e.g. P01, P02, ..., P78).
- Random number generator (RNG): here, instead of a simple counter, a random number generator is used where the link to the identifiers is even less predictable.
PRACTICAL: Counter and Random Number Generator applied in MS Excel 365
Adding a counter to a dataset is an easy solution to generate pseudonyms. It suffices to replace an identifier (e.g. "participant name") with a number or string. In Microsoft Excel, for example, you can do this by adding a column to the dataset where you enter some pseudonyms. In the example below, we added P001, P002 & P003 manually. When you select these, you can expand the selection by dragging down the green square at the bottom of the selection (see image). Excel will then automatically number further (P004, P005, etc.).
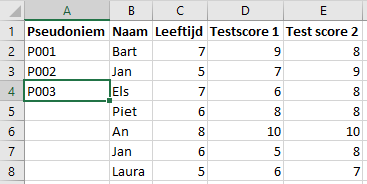
After this, you can copy the columns "Pseudonym" and "Name" to a new file. This will be your keyfile. You can now delete the "Name" column from your original dataset, which will make it pseudonymised. Note that many programs and/or cloud platforms save old/previous versions of files by default. When the version history of a file is saved, the "Name" column is also saved! However, you can easily write the values of the dataset to a new file where the version history is not included.
A potential disadvantage of this method of pseudonymisation is that the pseudonym counter displays information about the order of a dataset. This shortcoming can be remedied by giving records random pseudonyms. This option is also available in MS Excel 365, but is slightly more complex and involves applying the following formula:
=INDEX(UNIQUE(RANDARRAY(5^2;1;7;20;TRUE));SEQUENCE(5))
This formula will provide a column of 5 random, unique numbers between 7 and 20 (the range). To generate more numbers, simply replace the 5 in the formula twice with a number relevant to the size of the dataset (for example, by 200 if your dataset contains 200 records). The range should also be adjusted accordingly; it is recommended to define the range larger than the number of records. The range in the above formulas is defined by the numbers 7 and 20 and can be adjusted according to your preference. For example, if you have a dataset with 200 records (rows in MS Excel) and want to give each of them a unique number between 2 and 500, you should use the following modified formula:
=INDEX(UNIQUE(RANDARRAY(200^2;1;2;500;TRUE));SEQUENCE(200))
Hashing
In addition to counter and random number generator, hashing is also used in some cases. Hashing is a process in which information is converted into a fixed-length code (the 'hash' or 'hash code') by applying an algorithm (the 'hash function'). A hash code consists of a sequence of seemingly random numbers and letters. What is unique about hashing, is that it only works in one direction. You can convert information into a hash code via the hash function, but you cannot convert the hash code back to the original information. An advantage is that there is thus no need to keep a table with the link between the pseudonym and the identity. However, this is also immediately the major disadvantage of this technique: by hashing combinations of personal data and comparing the resulting codes, it is possible to 'guess' who the generated code belongs to. This makes this form of hashing unsuitable for pseudonymisation. To securely generate hash codes, additional measures such as adding a secret 'key' and possibly a 'salt' are indispensable. Hashes can be created, for example, in R with the openssl library or in Python with the hashlib library.
More information and practical examples can be found in ENISA's "Pseudonymisation techniques and best practices" report.
Pseudonymisation in R
R is a widely used programming language for processing and analysing datasets. Of course, it is also possible to pseudonymise your dataset in R. On this Github page, you can find instructions on how to generate Counter pseudonyms, Random Number Generator pseudonyms, as well as how to generate hashes via R.
More tips
- GDPR: how can I ensure that the processing of personal data is lawful? (Research integrity & ethics)
- GDPR: how do I protect my data correctly? (Research integrity & ethics)
- GDPR: how do I register personal data processing activities? (Research integrity & ethics)
- GDPR: what are personal data? (Research integrity & ethics)
- GDPR: What should I take into account when developing or using AI? (Research integrity & ethics)
Translated tip
Last modified Aug. 26, 2025, 11:14 a.m.